To make the simulation look better, we could add little color variation to the grains of sand. So let's do that first. We have already enabled different colors in our MatterWithColor struct, but we just are not using that capability yet. Add rand to dependencies.
# Cargo.toml
rand = "0.8.5"// matter.rs
use rand::Rng;
// Replace the impl in MatterId with the following
impl MatterId {
fn color_rgba_u8(&self) -> [u8; 4] {
let color = match *self {
MatterId::Empty => EMPTY_COLOR,
MatterId::Sand => 0xc2b280ff,
MatterId::Wood => 0xba8c63ff,
};
u32_rgba_to_u8_rgba(color)
}
fn gen_variate_color_rgba_u8(&self) -> [u8; 4] {
let p = rand::thread_rng().gen::<f32>();
let color = self.color_rgba_f32();
let variation = -0.1 + 0.2 * p;
let r = ((color[0] + variation).clamp(0.0, 1.0) * 255.0) as u8;
let g = ((color[1] + variation).clamp(0.0, 1.0) * 255.0) as u8;
let b = ((color[2] + variation).clamp(0.0, 1.0) * 255.0) as u8;
let a = 255;
[r, g, b, a]
}
fn color_rgba_f32(&self) -> [f32; 4] {
let rgba = self.color_rgba_u8();
[
rgba[0] as f32 / 255.0,
rgba[1] as f32 / 255.0,
rgba[2] as f32 / 255.0,
rgba[3] as f32 / 255.0,
]
}
}
impl MatterWithColor {
/// Creates a new matter with color from matter id giving it a slightly randomized color
pub fn new(matter_id: MatterId) -> MatterWithColor {
let color = if matter_id != MatterId::Empty {
matter_id.gen_variate_color_rgba_u8()
} else {
matter_id.color_rgba_u8()
};
MatterWithColor {
value: u8_rgba_to_u32_rgba(color[0], color[1], color[2], matter_id as u8),
}
}
//...
}First we convert the u32 color value to four f32s, randomize those with small variation and convert them back to u32. We'll use this when we create new matter. However, we don't do that to empty. Now sand has a varying color.
Let's also add a performance timer to track our simulation performance over time. Add timer.rs (and mod timer; to main.rs).
use std::{collections::VecDeque, time::Instant};
const NUM_TIME_SAMPLES: usize = 150;
/// A simple performance timer with a buffer of delta times to track performance over time
pub struct PerformanceTimer {
time: Instant,
data: VecDeque<f64>,
}
impl PerformanceTimer {
pub fn new() -> Self {
Self {
time: Instant::now(),
data: VecDeque::new(),
}
}
pub fn start(&mut self) {
self.time = Instant::now()
}
#[allow(unused)]
pub fn end(&self) -> f64 {
Instant::now().duration_since(self.time).as_nanos() as f64 / 1_000_000.0
}
pub fn time_it(&mut self) {
let time = Instant::now().duration_since(self.time).as_nanos() as f64 / 1_000_000.0;
self.data.push_back(time);
if self.data.len() >= NUM_TIME_SAMPLES {
self.data.pop_front();
}
}
pub fn time_average_ms(&self) -> f64 {
self.data.iter().sum::<f64>() / self.data.len() as f64
}
}
impl Default for PerformanceTimer {
fn default() -> Self {
PerformanceTimer::new()
}
}
pub struct SimTimer(pub PerformanceTimer);
pub struct RenderTimer(pub PerformanceTimer);
The purpose of this timer is to push our specified timed code sections to a queue and display their average in our user interface. Let's add our usage of this timer next.
Add following to setup in main.
// Simulation performance timer
let perf_timer = PerformanceTimer::new();
let render_timer = PerformanceTimer::new();
commands.insert_resource(SimTimer(perf_timer));
commands.insert_resource(RenderTimer(render_timer));And use it in the corresponding systems:
fn simulate(
mut sim_pipeline: ResMut<CASimulator>,
settings: Res<DynamicSettings>,
mut sim_timer: ResMut<SimTimer>,
) {
sim_timer.0.start();
//...
sim_timer.0.time_it();
}
fn render(
//...
mut render_timer: ResMut<RenderTimer>,
) {
render_timer.0.start();
//...
render_timer.0.time_it();
}Last, display it in the GUI.
// gui.rs
pub fn user_interface(
//...
sim_timer: Res<SimTimer>,
render_timer: Res<RenderTimer>,
) {
//...
.show(&ctx, |ui| {
//...
// Add this too for minor utility
sized_text(
ui,
format!("Grid size: ({},{})", CANVAS_SIZE_X, CANVAS_SIZE_Y),
size,
);
sized_text(
ui,
format!(
"Sim Time: {:.2} ms, {}",
sim_timer.0.time_average_ms(),
if settings.is_paused {
"Paused"
} else {
"Playing"
}
),
size,
);
sized_text(
ui,
format!("Render Time: {:.2} ms", render_timer.0.time_average_ms()),
size,
);
//...
}
Now you should see render and sim times in the GUI. You'll be able to see how tweaking canvas size, work group sizes, and your code affects performance. This probably won't be enough, but it's something :).
Next, we'll add the ability to adjust the move_steps of the simulation so our sand can move a bit faster.
// main.rs
pub struct DynamicSettings {
//...
pub move_steps: u32,
}
impl Default for DynamicSettings {
fn default() -> Self {
Self {
//...
move_steps: 1,
}
}
}
fn simulate(
mut sim_pipeline: ResMut<CASimulator>,
settings: Res<DynamicSettings>,
mut sim_timer: ResMut<SimTimer>,
) {
sim_timer.0.start();
sim_pipeline.step(settings.move_steps /*New!*/, settings.is_paused);
sim_timer.0.time_it();
}And to GUI
ui.add(egui::Slider::new(&mut settings.brush_radius, 0.5..=20.0).text("Brush Size"));
ui.add(egui::Slider::new(&mut settings.move_steps, 1..=5).text("Move Steps")); // New!The move step will now affect how many steps we'll take per simulation step for movement dispatches.
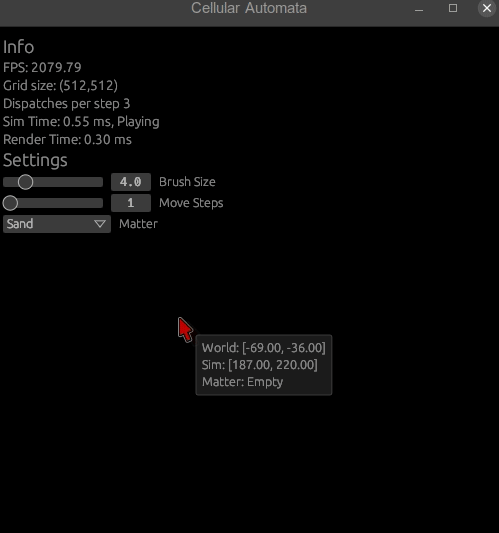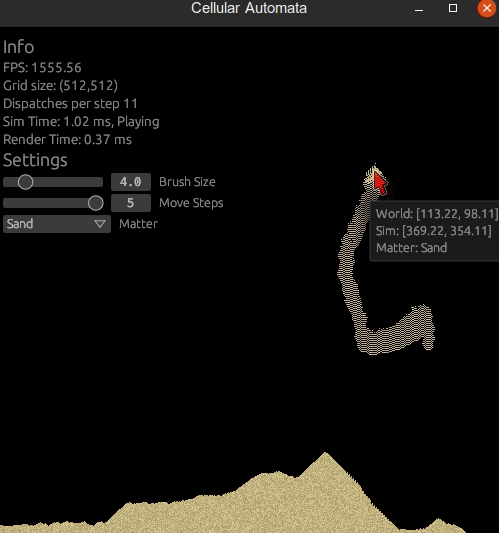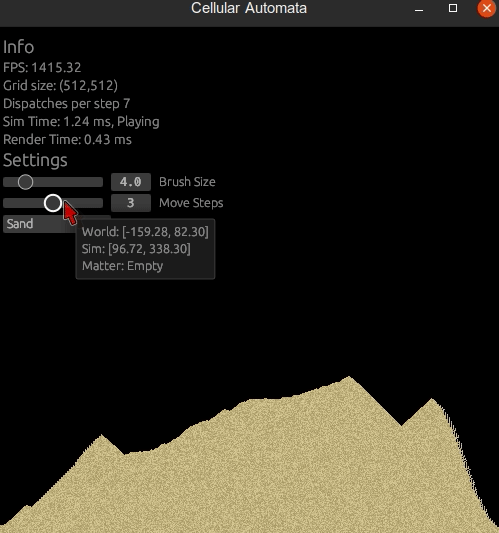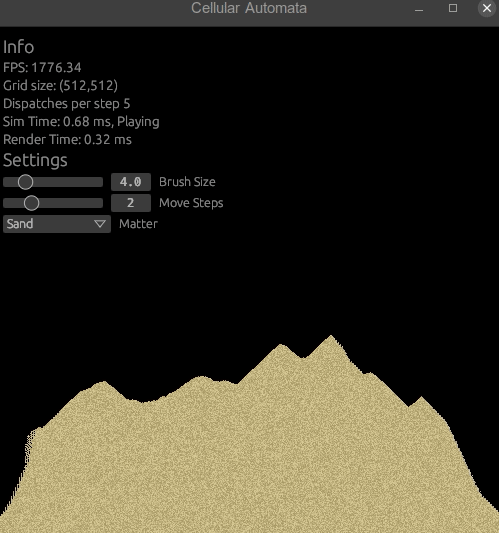
You can also add dispatches_per_step to see at what kind of dispatch numbers you'll be running into performance issues. Though it all can depend on the work group sizes, local sizes, memory usage and other parts of the code too.
// ca_simulator.rs
// Add to `CASimulator`, init to 0 in new
pub dispatches_per_step: u32,
// Zero it at the beginning of `step`
self.dispatches_per_step = 0;
// And increment it at dispatch
self.dispatches_per_step += 1;Display it in GUI under Info title.
// gui.rs
sized_text(
ui,
format!("Dispatches per step {}", simulator.dispatches_per_step),
size,
);Last thing I wanted to do was to grey scale the colors. Why? I've been thinking that a black and white pixel simulator could look cool. It might be silly, but it doesn't hurt to try. Let's add some functionality for that.
Add grey scale function to utils.rs
// utils.rs
/// Converts u32 color to gray scale for a wanted visual effect
/// https://stackoverflow.com/questions/42516203/converting-rgba-image-to-grayscale-golang
pub fn grey_scale_u32(color: u32) -> u32 {
let color = u32_rgba_to_u8_rgba(color);
let r = (0.299 * color[0] as f32) as u8;
let g = (0.587 * color[1] as f32) as u8;
let b = (0.114 * color[2] as f32) as u8;
let y = r + g + b;
u8_rgba_to_u32_rgba(y, y, y, 255)
}Add toggle to main.rs
// main.rs
pub const GREY_SCALE: bool = true;
pub const CLEAR_COLOR: [f32; 4] = if GREY_SCALE { [0.8; 4] } else { [0.0; 4] };
pub const EMPTY_COLOR: u32 = if GREY_SCALE { 0xffffffff } else { 0x0 };We'll switch clear color and empty color based on the toggle. Let's also enable light mode to egui.
// main.rs
// In setup
// Set light mode
let ctx = vulkano_windows
.get_primary_window_renderer()
.unwrap()
.gui_context();
if GREY_SCALE {
ctx.set_visuals(Visuals::light());
} else {
ctx.set_visuals(Visuals::dark());
}And in matter.rs
impl MatterId {
fn color_rgba_u8(&self) -> [u8; 4] {
let color = match *self {
MatterId::Empty => EMPTY_COLOR,
MatterId::Sand => 0xc2b280ff,
MatterId::Wood => 0xba8c63ff,
};
if GREY_SCALE {
u32_rgba_to_u8_rgba(grey_scale_u32(color))
} else {
u32_rgba_to_u8_rgba(color)
}
}
//...
}Now isn't that cool?

We're pretty much done here. One last thing we probably want to do is to see how we can perform a larger grid.
pub const WIDTH: f32 = 1920.0;
pub const HEIGHT: f32 = 1080.0;
pub const CANVAS_SIZE_X: u32 = 1536;
pub const CANVAS_SIZE_Y: u32 = 1536;
pub const LOCAL_SIZE_X: u32 = 32;
pub const LOCAL_SIZE_Y: u32 = 32;We're running a canvas 9 times larger than a typical 512x512 canvas.
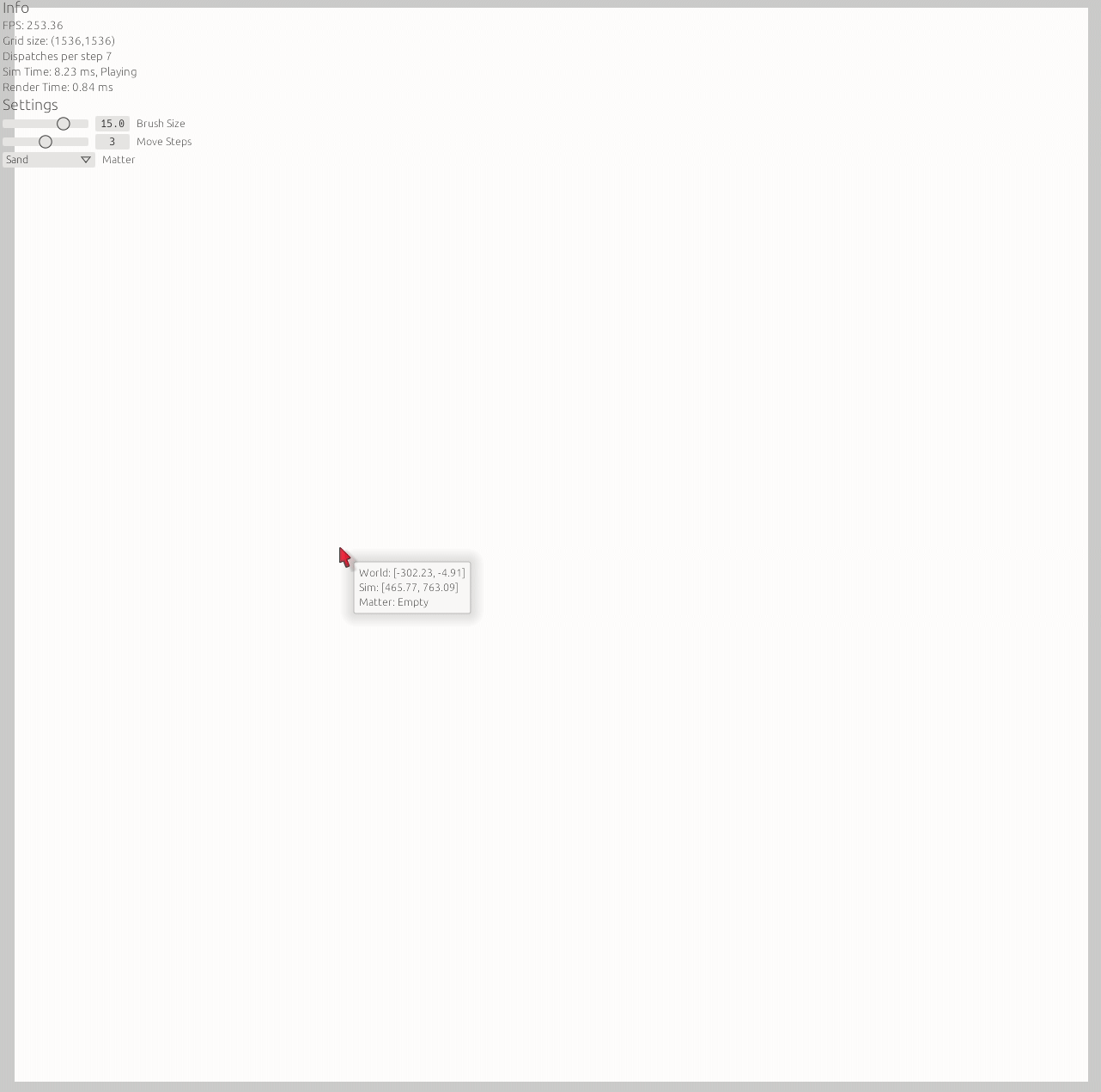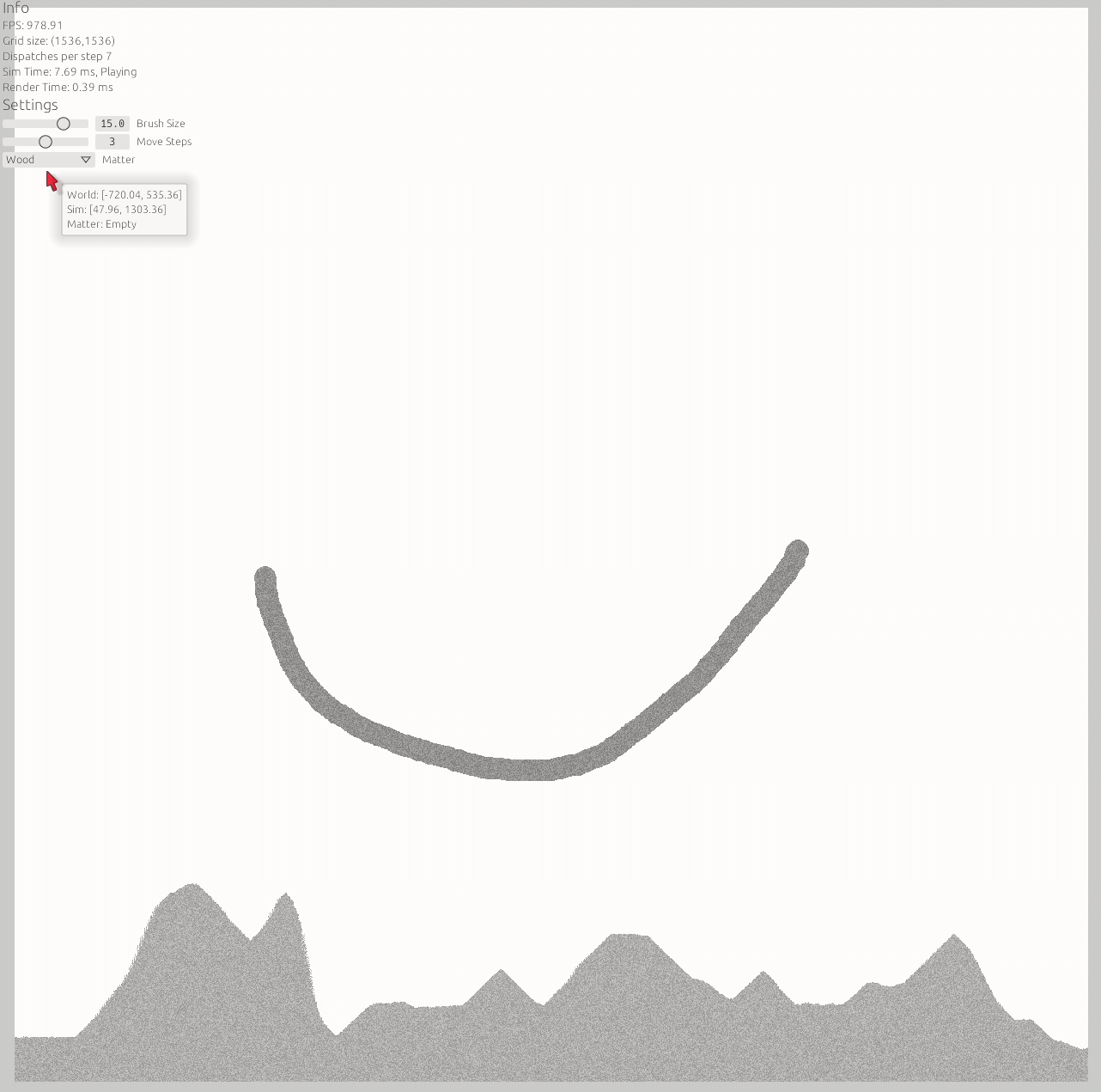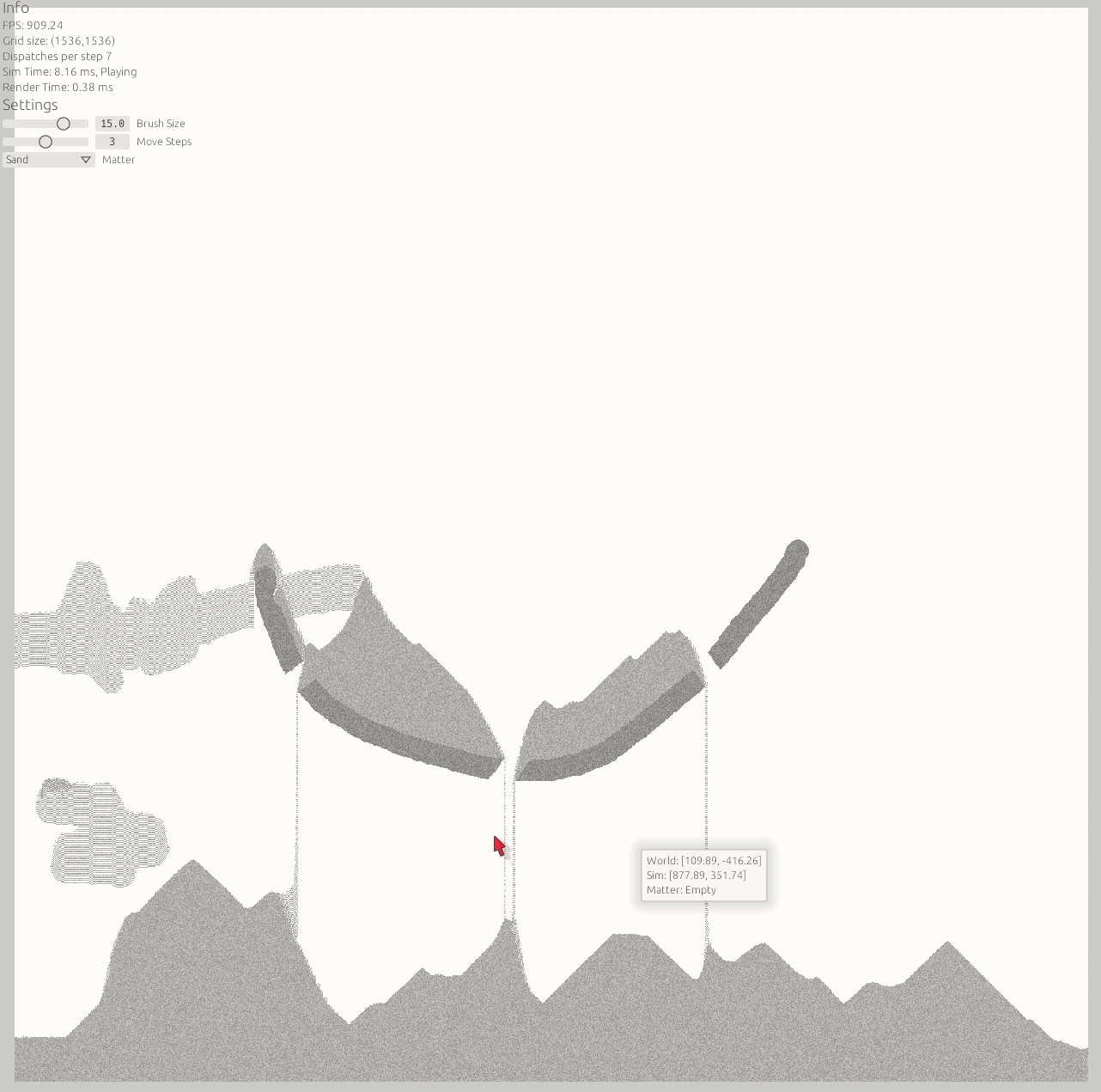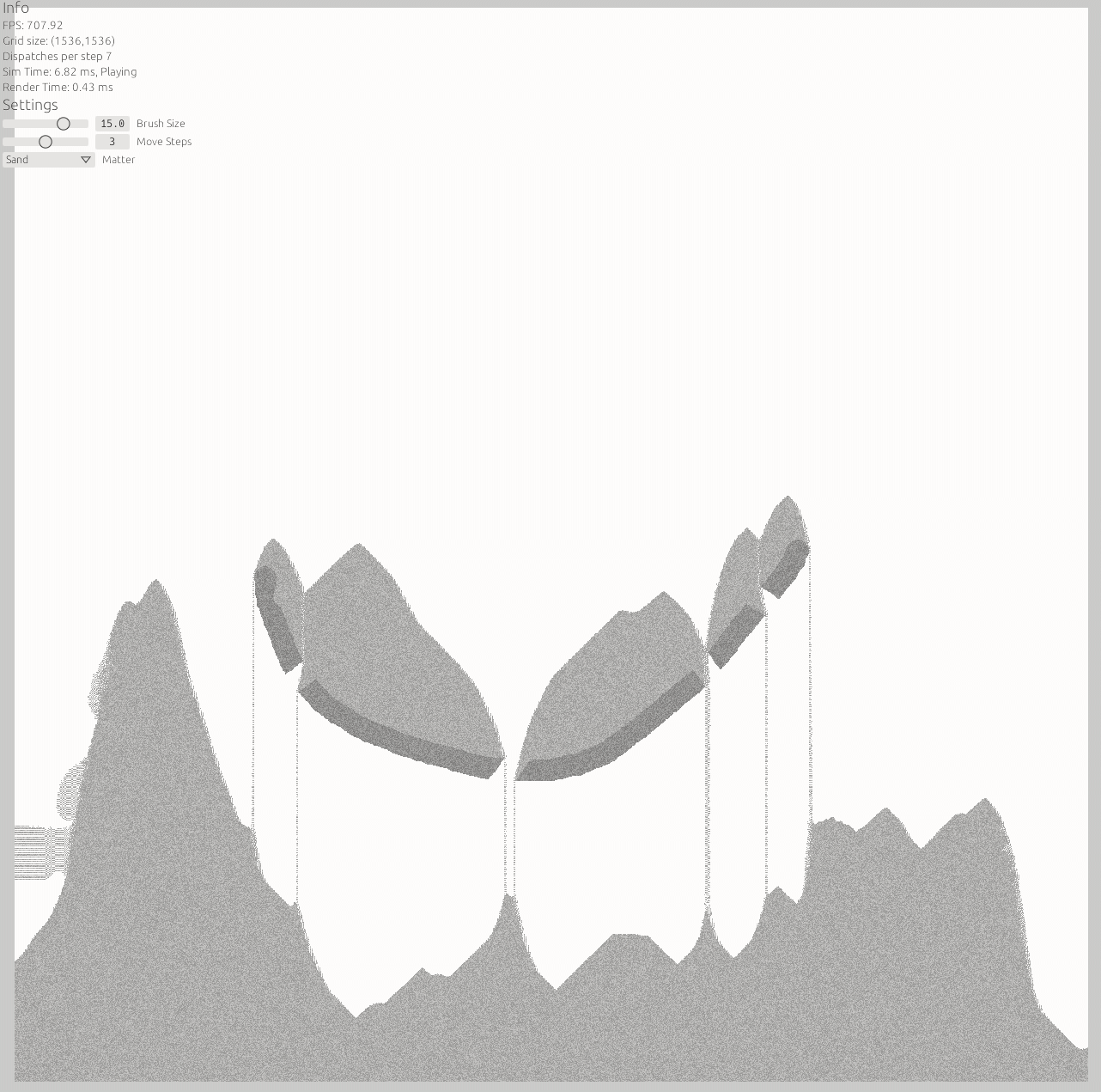
Looks great, performs well. Good job! My gaming laptop does not seem to run into hiccups until 4096x4096 (pretty badly). 2048x2048 is fine and more than enough pixels to have fun.
You could stop here and begin expanding on your code if you wish. The source code at this point can be found here. However, I want us to explore the performance capabilities a bit deeper.
Improving performance with DeviceLocalBuffer
So far we've been simply using CpuAccessibleBuffer for our grid. The reason for using that is that it is very easy to read and write from our Rust code. However, this flexibility comes at a performance cost. There exists a better alternative: DeviceLocalBuffer which resides only on the GPU side.
DeviceLocalBuffer: Buffer whose content is in device-local memory. This buffer type is useful in order to store intermediary data. For example you execute a compute shader that writes to this buffer, then read the content of the buffer in a following compute or graphics pipeline.
Such buffers should give a significant performance boost because the data is never accessed by anything but the GPU. The reason we did not use that earlier is that CpuAccessibleBuffers are much easier and straightforward to work with. You can simply get things done faster. But with this new approach, we'll have to add more compute shaders to do even the most simple thing, such as querying matter from the grid. We will be moving logic from Rust side to glsl.
Let's do some setup work first. Remove the following dependencies from Cargo.toml. We will be varying colors on the GPU side ourselves and we'll have to draw our lines there too.
rand = "0.8.5" #remove
line_drawing = "1.0.0" #removeRemove the function get_canvas_line in utils.rs and its usages. Remove gen_variate_color_rgba_u8 and color_rgba_f32 in matter.rs. And modify the MatterWithColor::new function like this.
// matter.rs
// New MatterWithColor::new
pub fn new(matter_id: MatterId) -> MatterWithColor {
let color = if matter_id != MatterId::Empty {
matter_id.gen_variate_color_rgba_u8()
} else {
matter_id.color_rgba_u8()
};
MatterWithColor {
value: u8_rgba_to_u32_rgba(color[0], color[1], color[2], matter_id as u8),
}
}Modify draw_matter in main.rs
//...
if mouse_button_input.pressed(MouseButton::Left) {
let end = current.canvas_pos();
let start = if let Some(prev) = prev.0 {
prev.canvas_pos()
} else {
end
};
simulator.draw_matter(start, end, settings.brush_radius, settings.draw_matter);
}
//...You can see that we don't have a line anymore, but start and end positions. This means we'll have to modify our drawing function in the simulator too (soon).
Remove dispatches per step text in gui.rs. It will be useless for now...
// Remove
sized_text(
ui,
format!("Dispatches per step {}", simulator.dispatches_per_step),
size,
);Then the beef: The simulator. Change empty_grid to create DeviceLocalBuffers.
fn device_grid(
compute_queue: &Arc<Queue>,
width: u32,
height: u32,
) -> Arc<DeviceLocalBuffer<[u32]>> {
DeviceLocalBuffer::array(
compute_queue.device().clone(),
(width * height) as DeviceSize,
BufferUsage::storage_buffer() | BufferUsage::transfer_dst(),
compute_queue.device().active_queue_families(),
)
.unwrap()
}And modify the simulator. A lot.
use vulkano::buffer::DeviceLocalBuffer;
/// Cellular automata simulation pipeline
pub struct CASimulator {
compute_queue: Arc<Queue>,
fall_pipeline: Arc<ComputePipeline>,
slide_pipeline: Arc<ComputePipeline>,
color_pipeline: Arc<ComputePipeline>,
// New two pipelines!
draw_matter_pipeline: Arc<ComputePipeline>,
query_matter_pipeline: Arc<ComputePipeline>,
// New types for our grid
matter_in: Arc<DeviceLocalBuffer<[u32]>>,
matter_out: Arc<DeviceLocalBuffer<[u32]>>,
// New buffer for us to write queried matter to a buffer
query_matter: Arc<CpuAccessibleBuffer<[u32]>>,
image: DeviceImageView,
pub sim_step: u32,
move_step: u32,
// New push constants!
draw_radius: f32,
draw_matter: MatterWithColor,
draw_pos_start: Vec2,
draw_pos_end: Vec2,
query_pos: IVec2,
}
impl CASimulator {
pub fn new(compute_queue: Arc<Queue>) -> CASimulator {
//...
let matter_in = device_grid(&compute_queue, CANVAS_SIZE_X, CANVAS_SIZE_Y);
let matter_out = device_grid(&compute_queue, CANVAS_SIZE_X, CANVAS_SIZE_Y);
let query_matter = CpuAccessibleBuffer::from_iter(
compute_queue.device().clone(),
BufferUsage::storage_buffer() | BufferUsage::transfer_dst(),
false,
vec![MatterWithColor::from(0).value],
)
.unwrap();
//...
//New pipelines! Means new shaders too :)
let (
fall_pipeline,
slide_pipeline,
color_pipeline,
draw_matter_pipeline,
query_matter_pipeline,
) = {
let fall_shader = fall_empty_cs::load(compute_queue.device().clone()).unwrap();
let slide_shader = slide_down_empty_cs::load(compute_queue.device().clone()).unwrap();
let color_shader = color_cs::load(compute_queue.device().clone()).unwrap();
let draw_matter_shader = draw_matter_cs::load(compute_queue.device().clone()).unwrap();
let query_matter_shader =
query_matter_cs::load(compute_queue.device().clone()).unwrap();
// This must match the shader & inputs in dispatch
let descriptor_layout = [
(0, storage_buffer_desc()),
(1, storage_buffer_desc()),
(2, storage_image_desc()),
// New buffer input to our layout :)
(3, storage_buffer_desc()),
];
(
create_compute_pipeline(
compute_queue.clone(),
fall_shader.entry_point("main").unwrap(),
descriptor_layout.to_vec(),
&spec_const,
),
create_compute_pipeline(
compute_queue.clone(),
slide_shader.entry_point("main").unwrap(),
descriptor_layout.to_vec(),
&spec_const,
),
create_compute_pipeline(
compute_queue.clone(),
color_shader.entry_point("main").unwrap(),
descriptor_layout.to_vec(),
&spec_const,
),
create_compute_pipeline(
compute_queue.clone(),
draw_matter_shader.entry_point("main").unwrap(),
descriptor_layout.to_vec(),
&spec_const,
),
create_compute_pipeline(
compute_queue.clone(),
query_matter_shader.entry_point("main").unwrap(),
descriptor_layout.to_vec(),
&spec_const,
),
)
};
// Create color image
let image = StorageImage::general_purpose_image_view(
compute_queue.clone(),
[CANVAS_SIZE_X, CANVAS_SIZE_Y],
Format::R8G8B8A8_UNORM,
ImageUsage {
sampled: true,
transfer_dst: true,
storage: true,
..ImageUsage::none()
},
)
.unwrap();
CASimulator {
compute_queue,
fall_pipeline,
slide_pipeline,
color_pipeline,
draw_matter_pipeline,
query_matter_pipeline,
matter_in,
matter_out,
query_matter,
image,
sim_step: 0,
move_step: 0,
draw_radius: 0.0,
draw_matter: MatterWithColor::from(0),
draw_pos_start: Vec2::new(0.0, 0.0),
draw_pos_end: Vec2::new(0.0, 0.0),
query_pos: IVec2::new(0, 0),
}
}
//...
}We have added new pipelines: draw_matter_pipeline and query_matter_pipeline. We used to read this from the previously CPU accessible buffer, but now we need to create dispatch commands and shaders for those (pipelines).
We can get rid of the index function too, that won't be needed on the CPU side anymore.
Now. Let's modify our drawing and querying to become compute shader dispatch. commands.
While working on this tutorial, I tried using the line_drawing functionality and sending a dispatch for each line point, and then drawing a circle in the compute shader. One can imagine that the app becomes rather slow when your line could be hundreds of pixels long. We want to minimize the number of dispatches. Thus we will be creating our own line drawing in the shader. But first, let's just modify the drawing and query functions Rust side.
// New function! (to reduce verbosity)
fn command_buffer_builder(&self) -> AutoCommandBufferBuilder<PrimaryAutoCommandBuffer> {
AutoCommandBufferBuilder::primary(
self.compute_queue.device().clone(),
self.compute_queue.family(),
CommandBufferUsage::OneTimeSubmit,
)
.unwrap()
}
// New function (to reduce verbosity)
fn execute(
&self,
command_buffer_builder: AutoCommandBufferBuilder<PrimaryAutoCommandBuffer>,
wait: bool,
) {
let command_buffer = command_buffer_builder.build().unwrap();
let finished = command_buffer.execute(self.compute_queue.clone()).unwrap();
let future = finished.then_signal_fence_and_flush().unwrap();
if wait {
future.wait(None).unwrap();
}
}
/// Query matter at pos
pub fn query_matter(&mut self, pos: IVec2) -> Option<MatterId> {
if self.is_inside(pos) {
self.query_pos = pos;
// Build command buffer
let mut command_buffer_builder = self.command_buffer_builder();
// Dispatch
self.dispatch(
&mut command_buffer_builder,
self.query_matter_pipeline.clone(),
false,
);
// Execute & finish (wait)
self.execute(command_buffer_builder, true);
// Read result
let query_matter = self.query_matter.read().unwrap();
Some(MatterWithColor::from(query_matter[0]).matter_id())
} else {
None
}
}
/// Draw matter line with given radius
pub fn draw_matter(&mut self, start: Vec2, end: Vec2, radius: f32, matter: MatterId) {
// Update our variables to be used as push constants
self.draw_pos_start = start;
self.draw_pos_end = end;
self.draw_matter = MatterWithColor::new(matter);
self.draw_radius = radius;
// Build command buffer
let mut command_buffer_builder = self.command_buffer_builder();
// Dispatch
self.dispatch(
&mut command_buffer_builder,
self.draw_matter_pipeline.clone(),
false,
);
// Execute & finish (no need to wait)
self.execute(command_buffer_builder, false);
}We've changed our querying and drawing to become compute shader dispatches. You'll see that the query has to wait on the dispatch to finish, because it reads the data from the CpuAccessibleBuffer to which the shader will write the result. Unless we wait, the read can panic.
Modify the step to be cleaner too.
/// Step simulation
pub fn step(&mut self, move_steps: u32, is_paused: bool) {
let mut command_buffer_builder = self.command_buffer_builder();
if !is_paused {
for _ in 0..move_steps {
self.step_movement(&mut command_buffer_builder, self.fall_pipeline.clone());
self.step_movement(&mut command_buffer_builder, self.slide_pipeline.clone());
}
}
// Finally color the image
self.dispatch(
&mut command_buffer_builder,
self.color_pipeline.clone(),
false,
);
// Execute & finish (no need to wait)
self.execute(command_buffer_builder, false);
self.sim_step += 1;
}Then, we'll add the new inputs to the dispatch function.
fn dispatch(
&mut self,
builder: &mut AutoCommandBufferBuilder<PrimaryAutoCommandBuffer>,
pipeline: Arc<ComputePipeline>,
swap: bool,
) {
let pipeline_layout = pipeline.layout();
let desc_layout = pipeline_layout.set_layouts().get(0).unwrap();
let set = PersistentDescriptorSet::new(desc_layout.clone(), [
WriteDescriptorSet::buffer(0, self.matter_in.clone()),
WriteDescriptorSet::buffer(1, self.matter_out.clone()),
WriteDescriptorSet::image_view(2, self.image.clone()),
// New buffer!
WriteDescriptorSet::buffer(3, self.query_matter.clone()),
])
.unwrap();
// New push constants!!
let push_constants = fall_empty_cs::ty::PushConstants {
sim_step: self.sim_step as u32,
move_step: self.move_step as u32,
draw_pos_start: self.draw_pos_start.into(),
draw_pos_end: self.draw_pos_end.into(),
draw_radius: self.draw_radius,
draw_matter: self.draw_matter.value,
query_pos: self.query_pos.into(),
};
builder
.bind_pipeline_compute(pipeline.clone())
.bind_descriptor_sets(PipelineBindPoint::Compute, pipeline_layout.clone(), 0, set)
.push_constants(pipeline_layout.clone(), 0, push_constants)
.dispatch([NUM_WORK_GROUPS_X, NUM_WORK_GROUPS_Y, 1])
.unwrap();
// Double buffering: Swap input and output so the output becomes the input for next frame
if swap {
std::mem::swap(&mut self.matter_in, &mut self.matter_out);
}
}And finally, add two more shaders. And add the files so they correspond to below paths.
mod draw_matter_cs {
vulkano_shaders::shader! {
ty: "compute",
path: "compute_shaders/draw_matter.glsl"
}
}
mod query_matter_cs {
vulkano_shaders::shader! {
ty: "compute",
path: "compute_shaders/query_matter.glsl"
}
}Don't forget to modify the tests too:
// Only this line
simulator.draw_matter(&[pos], 0.5, MatterId::Sand);
// To this
simulator.draw_matter(pos.as_vec2(), pos.as_vec2(), 0.5, MatterId::Sand);Last, we need to add the shader code. New additions to includes.glsl.
// New
layout(set = 0, binding = 3) restrict writeonly buffer QueryMatterBuffer { uint query_matter[]; };
// Modified
layout(push_constant) uniform PushConstants {
uint sim_step;
uint move_step;
vec2 draw_pos_start;
vec2 draw_pos_end;
float draw_radius;
uint draw_matter;
ivec2 query_pos;
} push_constants;
// New
void write_query_matter(Matter matter) {
query_matter[0] = matter_to_uint(matter);
}
// New
void write_matter_input(ivec2 pos, Matter matter) {
matter_in[get_index(pos)] = matter_to_uint(matter);
}
// Moved from colors.glsl for reusing. Now though 00rrggbb
vec4 matter_color_to_vec4(uint color) {
return vec4(float((color >> uint(16)) & uint(255)) / 255.0,
float((color >> uint(8)) & uint(255)) / 255.0,
float(color & uint(255)) / 255.0,
1.0);
}We've added the write_matter_input function because we must now write to the grid through a compute shader instead of the way it was before.
Then query_matter.glsl
#version 450
#include "includes.glsl"
void main() {
ivec2 pos = get_current_sim_pos();
if (pos == push_constants.query_pos) {
write_query_matter(read_matter(pos));
}
}Querying is super simple. We simply check if our pixel position corresponds to the query position. And if so, we write it to our 1 length buffer.
However, draw_matter.glsl is not so simple.
#version 450
#include "includes.glsl"
// https://stackoverflow.com/questions/4200224/random-noise-functions-for-glsl
float PHI = 1.61803398874989484820459; // Golden ratio
float rand(in vec2 xy, in float seed){
return fract(tan(distance(xy * PHI, xy) * seed) * xy.x);
}
vec4 vary_color_rgb(vec4 color, ivec2 seed_pos) {
// Just use the same seed (means same color for individual xy position)
float seed = 0.1;
float p = rand(seed_pos, seed);
float variation = -0.1 + 0.2 * p;
color.rgb += vec3(variation);
return color;
}
// 3. Convert uint to vec4, randomize rgb a bit, convert back
uint variate_color(ivec2 pos, uint color) {
vec4 color_f32 = matter_color_to_vec4(color);
vec4 variated_color_f32 = vary_color_rgb(color_f32, pos);
uint rgb = ((uint(variated_color_f32.r * 255.0) & uint(255)) << uint(16)) |
((uint(variated_color_f32.g * 255.0) & uint(255)) << uint(8)) |
(uint(variated_color_f32.b * 255.0) & uint(255));
return rgb;
}
// 2. Check if current pixel is within radius from draw position (closest point on line)
void draw_matter_circle(ivec2 pos, ivec2 draw_pos, float radius, Matter matter) {
int y_start = draw_pos.y - int(radius);
int y_end = draw_pos.y + int(radius);
int x_start = draw_pos.x - int(radius);
int x_end = draw_pos.x + int(radius);
if (pos.x >= x_start && pos.x <= x_end && pos.y >= y_start && pos.y <= y_end) {
vec2 diff = vec2(pos) - vec2(draw_pos);
float dist = length(diff);
if (round(dist) <= radius) {
// 3. Vary color only if not empty
if (!is_empty(matter)) {
matter.color = variate_color(pos, matter.color);
}
// 4. write matter to input buffer
write_matter_input(pos, matter);
}
}
}
// Line v->w, point p
// https://stackoverflow.com/questions/849211/shortest-distance-between-a-point-and-a-line-segment
vec2 closest_point_on_line(vec2 v, vec2 w, vec2 p) {
vec2 c = v - w;
// length squared
float l2 = dot(c, c);
if (l2 == 0.0) {
return v;
}
float t = max(0.0, min(1.0, dot(p - v, w - v) / l2));
vec2 projection = v + t * (w - v);
return projection;
}
void main() {
ivec2 pos = get_current_sim_pos();
// 1. Get closest point on the line defined by start and end from push constants
vec2 point_on_line = closest_point_on_line(push_constants.draw_pos_start, push_constants.draw_pos_end, pos);
// 2. Draw matter circle at the closest point on line
draw_matter_circle(
pos,
ivec2(point_on_line),
push_constants.draw_radius,
new_matter(push_constants.draw_matter)
);
}You can see there's a lot of similar logic here which previously resided on the Rust side. Let me explain the code a bit better though. The following can be seen reading through the main() function.
- Get closest point on line: Check current XY position and get closest position to it on the line. Line is determined by start and end positions, which come as push constants from Rust side.
- Draw matter circle: Pass the closest position as the draw position to our circle draw function. We simply check that the current position is inside the radius distance from the draw position. If that is true, we draw matter.
- If matter is not empty, we vary its color. This is done with a position dependent
randfunction. We convert theuinttovec4rgb color, add some randomness, and convert it back. - Write to matter input grid.
We should be good to go now. Try running it! cargo test should also pass. Though, it looks like our grid background (for empty color) is black if GREY_SCALE is true. Fix it with the following.
// main
// After this line in setup function
let mut sim_pipeline = CASimulator::new(primary_window_renderer.compute_queue());
// Add this. This ensures we initialize the grid with empty matter (which should be white)
if GREY_SCALE {
let start = Vec2::new(CANVAS_SIZE_X as f32, CANVAS_SIZE_Y as f32) / 2.0;
let end = start;
sim_pipeline.draw_matter(start, end, CANVAS_SIZE_X as f32, MatterId::Empty);
}Run it now. At 512 x 512 a pleasing 2000+ FPS. Time to test the performance at 8k.
- 8192 x 8192 runs nicely above 300 FPS on my gaming laptop with
GeForce RTX 2070 with Max-Q Design, type: DiscreteGpu, mem: 4.00 gb. - 10240 x 10240 runs 60-150 FPS. I find that incredible. Our grid is now 400 times larger than a typical 512 GPU grid. On a laptop. Mic drop.
I'll finish with a gif of 4096 x 4096 at 5 move steps per frame. Before DeviceLocalBuffer this was not runnable at just 1 move step.
We're done!
You can checkout the full source code for this tutorial here. And don't hesitate to star the repo if you found this inspiring.
Ending Notes
I hope this tutorial has sparked an interest towards compute shaders and cellular automata for you. Or even better, towards Rust or Vulkano (and Vulkan). This can be a great starting point for rendering fractals, or making your own ray tracer, both being good examples of where you are doing calculation for each pixel.
For some further ideas on how to expand on this, you can check out my sandbox repository which implements pixel objects, liquids and gases and much more on top of just sand fall. I've also been working on a game based on this type of approach.
Some next challenges for you could be:
- Debugging with Renderdoc.
- Implementing more materials
- Arbitrary gravity direction
If you want to support my work financially, you can do so here.
Give feedback here
Was this page helpful?