Time for some Sand to Fall.
If you were to do this single threaded, you could just loop through your grid and for each cell you could check what's under (depending on your rules) and place it there if it's empty. Simple. You would be "pushing" the cell outwards from its current position. You'd probably be able to run this on canvases of up to 256x256 depending on your fps target, system and code optimization. And you might have to consider the iteration order depending on the direction you are checking, if you are using only a single buffer.
However, if you were to do all that in parallel, you'd need to think through the problem a bit differently. That's because one thread might be looking at the cell above, determine that it can move down and write it there. However, simultaneously another thread might be looking at the cell down and determine it's empty or that it has sand. Either of those can happen. Eventually you'd run into inconsistencies. To solve this Noita developers said:
you’d have to add atomics or locks to make sure that the value is up to date on all threads. And that would slow things down a lot
There are ways to go around this, but in the case of CPU you usually don't have that many threads. With GPU we might have a thousand or more. So the inconsistencies would eventually happen if you were to push cells to other cells, meaning you'd be writing elsewhere than the "current" cell. You could map your grid differently and utilize shared memory. However that would be a lot more work. What if you would determine the state of each cell completely independently.
A great example of this is the Game of Life. You can determine the state of each cell by its neighbors, then write the new state to an output buffer, and repeat each frame swapping the output buffer to be the new input. Each pixel calculation can be done independently of each other despite the neighbor relations. Or a fractal. These are what you'd call embarrassingly parallel. We want that.
1. Read Buffer Input
2. Determine new state
3. Write Buffer Output
4. Swap Buffer Input and Buffer Output
RepeatSo how would we do this for cells that are actually moving (seemingly)? Similarly to the Game Of Life, we'll be using what you'd call a pull strategy. Each cell checks the neighboring cell(s) and determines their next state based on that. But we'll be splitting the movement to multiple dispatch steps also known as passes.
Let's begin with some pre work by adding a matter with color struct for us instead of having just an u32 color. Add file called matter.rs. To save memory (faster computation), we'll be bundling our red, green and blue with MatterId to one u32. Add strum_macros and strum to dependencies for easy enum iteration.
The more data you are packing to the buffers passed to shaders, the more data the individual shader invocation has to access. And the more data it has to read or write, the slower your computation becomes.
# Cargo.toml
strum_macros = "0.24.0"
strum = "0.24.0"// matter.rs
use strum_macros::EnumIter;
use crate::{
utils::{u32_rgba_to_u8_rgba, u8_rgba_to_u32_rgba},
EMPTY_COLOR,
};
/// Matter identifier representing matter that we simulate
#[repr(u8)]
#[derive(EnumIter, Debug, Copy, Clone, Eq, PartialEq)]
pub enum MatterId {
Empty = 0,
Sand = 1,
Wood = 2,
}
impl Default for MatterId {
fn default() -> Self {
MatterId::Empty
}
}
impl From<u8> for MatterId {
fn from(item: u8) -> Self {
unsafe { std::mem::transmute(item) }
}
}
impl MatterId {
fn color_rgba_u8(&self) -> [u8; 4] {
let color = match *self {
MatterId::Empty => EMPTY_COLOR,
MatterId::Sand => 0xc2b280ff,
MatterId::Wood => 0xba8c63ff,
};
u32_rgba_to_u8_rgba(color)
}
}
/// Matter data where first 3 bytes are saved for color and last 4th byte is saved for matter identifier
#[derive(Default, Copy, Clone)]
pub struct MatterWithColor {
pub value: u32,
}
impl MatterWithColor {
/// Creates a new matter with color from matter identifier giving it a slightly randomized color
pub fn new(matter_id: MatterId) -> MatterWithColor {
let color = matter_id.color_rgba_u8();
MatterWithColor {
value: u8_rgba_to_u32_rgba(color[0], color[1], color[2], matter_id as u8),
}
}
pub fn matter_id(&self) -> MatterId {
((self.value & 255) as u8).into()
}
}
impl From<u32> for MatterWithColor {
fn from(item: u32) -> Self {
Self {
value: item,
}
}
}
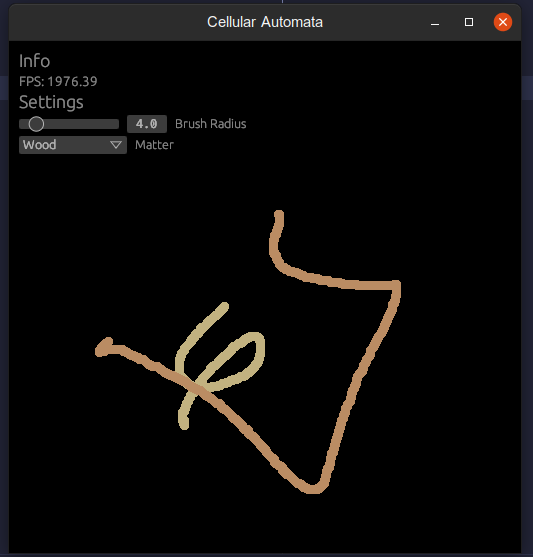
The colors are hex values first, but when we create a MatterWithColor we replace the alpha with the matter identifier. This means that we have space for 256 different matter identifiers, which will be plenty enough. In this tutorial, we only need 3.
Let's then add the ability to select matter in our GUI and settings. While at it, add a setting for pausing the simulation. Pausing will be useful, if you need to debug things later.
// main.rs
use crate::matter::MatterId;
pub struct DynamicSettings {
pub brush_radius: f32,
pub draw_matter: MatterId, // New
pub is_paused: bool, // New
}
impl Default for DynamicSettings {
fn default() -> Self {
Self {
brush_radius: 4.0,
draw_matter: MatterId::Sand, // New
is_paused: false, // New
}
}
}And then to gui
// gui.rs
use strum::IntoEnumIterator;
use crate::matter::MatterId;
pub fn user_interface(
//...
) {
//...
ui.add(egui::Slider::new(&mut settings.brush_radius, 0.5..=30.0).text("Brush Radius"));
// Selectable matter
egui::ComboBox::from_label("Matter")
.selected_text(format!("{:?}", settings.draw_matter))
.show_ui(ui, |ui| {
for matter in MatterId::iter() {
ui.selectable_value(
&mut settings.draw_matter,
matter,
format!("{:?}", matter),
);
}
});
});
}
And don't forget to modify draw_matter functionality in CASimulator to take matter id as the input.
// ca_simulator.rs
pub fn draw_matter(&mut self, line: &[IVec2], radius: f32, matter: MatterId /*New*/) {
//...
matter_in[self.index([x, y].into())] =
MatterWithColor::new(matter).value;
//...
}
One more thing remains before we can draw matter. We'll have to update our shaders. Let's create a new shader called includes.glsl and matter.glsl. We'll be placing our shared layout to includes (move from color.glsl). Also shared functions will go there. Go ahead and clear color.glsl too. Here are the new versions.
// includes.glsl
/*
Specialization constants
*/
layout(constant_id = 0) const int canvas_size_x = 1;
layout(constant_id = 1) const int canvas_size_y = 1;
layout(constant_id = 2) const uint empty_matter = 1;
layout(local_size_x_id = 3, local_size_y_id = 4, local_size_z = 1) in;
/*
Buffers
*/
layout(set = 0, binding = 0) restrict buffer MatterInBuffer { uint matter_in[]; };
layout(set = 0, binding = 1) restrict writeonly buffer MatterOutBuffer { uint matter_out[]; };
layout(set = 0, binding = 2, rgba8) restrict uniform writeonly image2D canvas_img;
#include "matter.glsl"
/*
Utility functions to be used in the various kernels:
*/
ivec2 get_current_sim_pos() {
return ivec2(gl_GlobalInvocationID.xy);
}
int get_index(ivec2 pos) {
return pos.y * canvas_size_x + pos.x;
}
bool is_inside_sim_canvas(ivec2 pos) {
return pos.x >= 0 && pos.x < canvas_size_x &&
pos.y >= 0 && pos.y < canvas_size_y;
}
// Changed!
Matter read_matter(ivec2 pos) {
return new_matter(matter_in[get_index(pos)]);
}
// New!
uint matter_to_uint(Matter matter) {
return ((matter.color << uint(8)) | matter.matter);
}
// Changed!
void write_matter(ivec2 pos, Matter matter) {
matter_out[get_index(pos)] = matter_to_uint(matter);
}
void write_image_color(ivec2 pos, vec4 color) {
imageStore(canvas_img, pos, color);
}Matter transforms the uint from the buffer to our matter struct.
// matter.glsl
struct Matter {
uint matter;
uint color;
};
Matter new_matter(uint matter) {
Matter m;
m.matter = (matter & uint(255));
m.color = matter >> uint(8);
return m;
}
// color.glsl
#version 450
#include "includes.glsl"
// Changed!
vec4 matter_color_to_vec4(uint color) {
return vec4(float((color >> uint(16)) & uint(255)) / 255.0,
float((color >> uint(8)) & uint(255)) / 255.0,
float(color & uint(255)) / 255.0,
1.0);
}
// 0-1 linear from 0-255 sRGB
vec3 linear_from_srgb(vec3 srgb) {
bvec3 cutoff = lessThan(srgb, vec3(10.31475));
vec3 lower = srgb / vec3(3294.6);
vec3 higher = pow((srgb + vec3(14.025)) / vec3(269.025), vec3(2.4));
return mix(higher, lower, cutoff);
}
vec4 linear_from_srgba(vec4 srgba) {
return vec4(linear_from_srgb(srgba.rgb * 255.0), srgba.a);
}
void write_color_to_image(ivec2 pos) {
Matter matter = read_matter(pos);
// Our swapchain is in SRGB color space (default by bevy_vulkano). The system tries to interpret our canvas image as such. But our canvas image is
// UNORM (only way to ImageStore), thus we need to convert the colors to linear space. We are assuming that images
// Are already in SRGB color space. When we render, the linear gets interpreted as SRGB.
write_image_color(pos, linear_from_srgba(matter_color_to_vec4(matter.color)));
}
void main() {
write_color_to_image(get_current_sim_pos());
}With these changes, you should be able to draw matter instead of drawing just a color. Well, it's still just a color from the image's perspective. We'll be focusing on just the sand's behavior. The wood exists there so we can have something that blocks the sand. In case you were wondering.
Okay, let's add ourselves a new compute shader pipeline. Add fall_empty.glsl to our compute shaders folder. First it will be just a shader that will read from our input buffer, and write to our output buffer. We'll edit it later.
#version 450
#include "includes.glsl"
void fall_empty(ivec2 pos) {
Matter current = read_matter(pos);
Matter m = current;
//... logic to be added here
write_matter(pos, m);
}
void main() {
fall_empty(get_current_sim_pos());
}And add the pipeline to CASimulator.
pub struct CASimulator {
//...
fall_pipeline: Arc<ComputePipeline>,
}
impl CASimulator {
pub fn new(compute_queue: Arc<Queue>) -> CASimulator {
//...
// Create pipelines
let (fall_pipeline, color_pipeline) = {
let fall_shader = fall_empty_cs::load(compute_queue.device().clone()).unwrap();
let color_shader = color_cs::load(compute_queue.device().clone()).unwrap();
// This must match the shader and inputs in dispatch
let descriptor_layout = [
(0, storage_buffer_desc()),
(1, storage_buffer_desc()),
(2, storage_image_desc()),
];
(
create_compute_pipeline(
compute_queue.clone(),
fall_shader.entry_point("main").unwrap(),
descriptor_layout.to_vec(),
&spec_const,
),
create_compute_pipeline(
compute_queue.clone(),
color_shader.entry_point("main").unwrap(),
descriptor_layout.to_vec(),
&spec_const,
),
)
};
//...
CASimulator {
//...
fall_pipeline,
//...
}
}
mod fall_empty_cs {
vulkano_shaders::shader! {
ty: "compute",
path: "compute_shaders/fall_empty.glsl"
}
}
//...Let's also dispatch it. Add following just before the dispatch of color_pipeline.
self.dispatch(&mut command_buffer_builder, self.fall_pipeline.clone());You can run it now, but we're still basically just drawing. So let's fix our fall_empty.glsl shader. Add following utility functions to includes.glsl.
#include "dirs.glsl"
bool is_at_border_top(ivec2 pos) {
return pos.y == canvas_size_y - 1;
}
bool is_at_border_bottom(ivec2 pos) {
return pos.y == 0;
}
bool is_at_border_right(ivec2 pos) {
return pos.x == canvas_size_x - 1;
}
bool is_at_border_left(ivec2 pos) {
return pos.x == 0;
}
ivec2 get_pos_at_dir(ivec2 pos, int dir) {
return pos + OFFSETS[dir];
}
// | 0 1 2 |
// | 7 x 3 |
// | 6 5 4 |
Matter get_neighbor(ivec2 pos, int dir) {
ivec2 neighbor_pos = get_pos_at_dir(pos, dir);
if (is_inside_sim_canvas(neighbor_pos)) {
return read_matter(neighbor_pos);
} else {
return new_matter(empty_matter);
}
}
bool is_empty(Matter matter) {
return matter.matter == 0;
}
// A shortcut for Sand. Wood does not have gravity for now...
bool is_gravity(Matter m) {
return m.matter == 1;
}
bool falls_on_empty(Matter from, Matter to) {
return is_gravity(from) && is_empty(to);
}And add dirs.glsl
/*
Grid Directions
*/
#define UP_LEFT 0
#define UP 1
#define UP_RIGHT 2
#define RIGHT 3
#define DOWN_RIGHT 4
#define DOWN 5
#define DOWN_LEFT 6
#define LEFT 7
/*
Neighbor Directions
*/
const ivec2 OFFSETS[8] = ivec2[8](ivec2(-1, 1), ivec2(0, 1), ivec2(1, 1), ivec2(1, 0),
ivec2(1, -1), ivec2(0, -1), ivec2(-1, -1), ivec2(-1, 0));Now we can read neighbor matters easily. Fix fall_empty.
//...
void fall_empty(ivec2 pos) {
Matter current = read_matter(pos);
Matter up = get_neighbor(pos, UP);
Matter down = get_neighbor(pos, DOWN);
Matter m = current;
if (!is_at_border_top(pos) && falls_on_empty(up, current)) {
m = up;
} else if (!is_at_border_bottom(pos) && falls_on_empty(current, down)) {
m = down;
}
write_matter(pos, m);
}
//...We've created some boolean logic to determine the state of the current cell. It goes like this:
- If there's a cell trying to fall from above, we change the current cell to be above.
- Else if the current cell is trying to go down, we change the current cell to be the empty one from below.
Both cannot be true at the same time. Example:
Thread 1 => Current cell is Empty, Sand is above => New state becomes Sand for next round
// Let's imagine thread 2 looking at the sand above thread 1.
Thread 2 => Current cell is Sand, first if can't be true, because up can't fall down, look at second if.
Second if determines that Sand will go down => New state becomes Empty for next round.Thus we have two threads coming to the same conclusion independently and write their new states correctly. How cool is that! The border util functions help with boundary conditions so we stay within the canvas. The trick here is though that we're going to need one pass per direction. Otherwise, we would run into inconsistencies. So we'll need a separate pipeline for diagonal movement.
Let's run it. Still not moving? Oh yes, we'll have to swap our input and output buffers. Modify the dispatch command.
//... In step()
self.dispatch(&mut command_buffer_builder, self.fall_pipeline.clone(), true);
// We don't swap when we color, because we only write the color to the image
self.dispatch(&mut command_buffer_builder, self.color_pipeline.clone(), false);
//...
fn dispatch(
&mut self,
//...
swap: bool, //New
) {
//...
// Double buffering: Swap input and output so the output becomes the input for next frame
if swap {
std::mem::swap(&mut self.matter_in, &mut self.matter_out);
}
}We can now draw skyscrapers! This would be an example of a typical rock matter behavior.
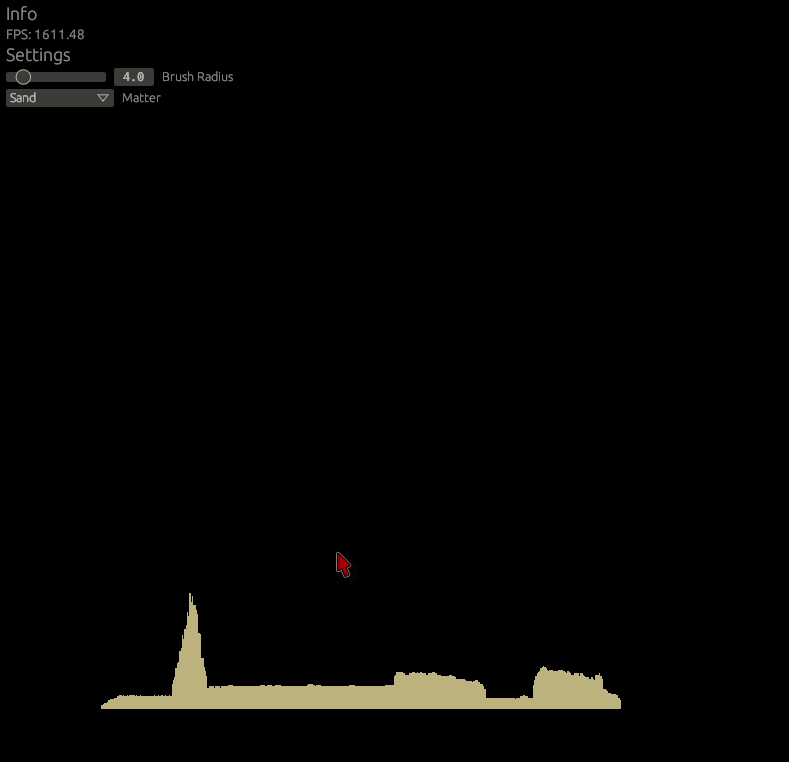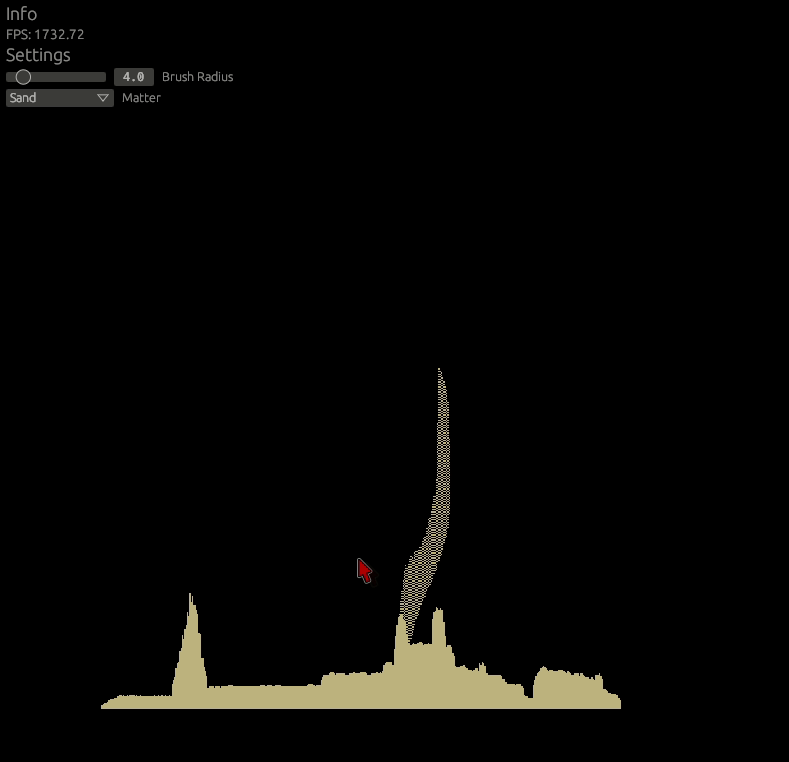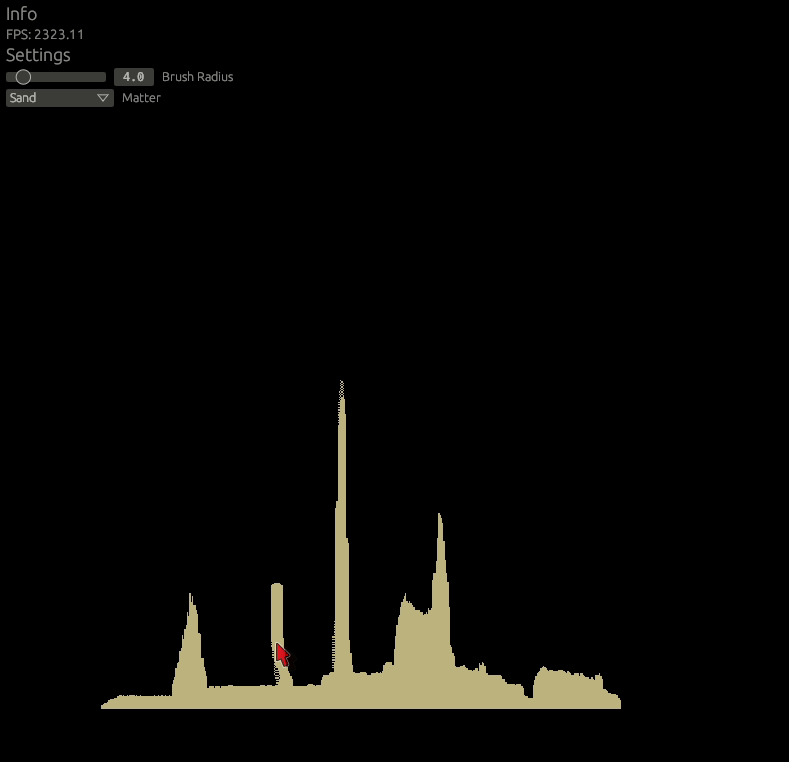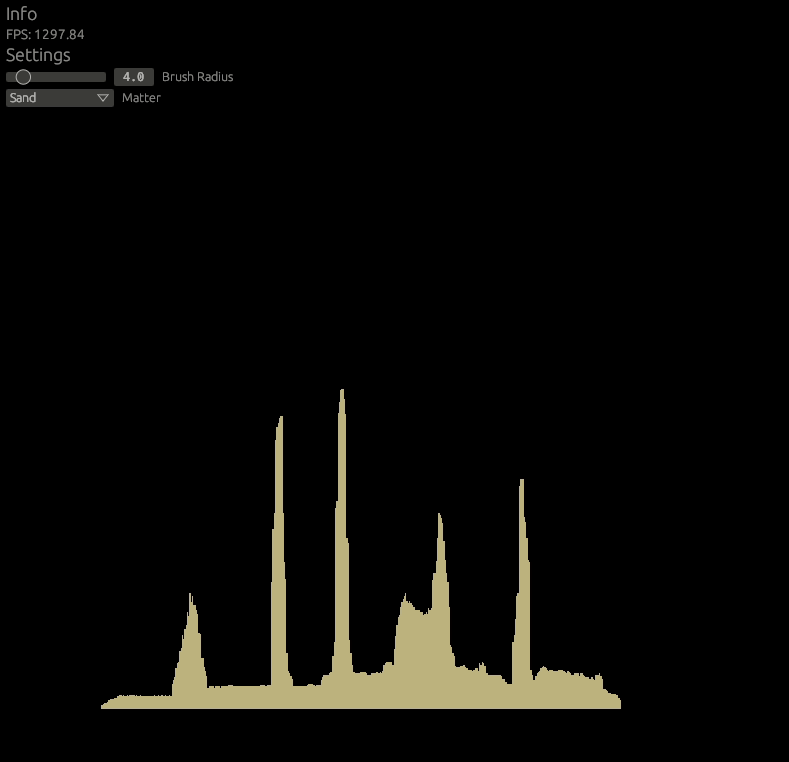
Let's do the diagonal movement then. Add following to the includes.glsl.
//includes.glsl
bool slides_on_empty(Matter from_diagonal, Matter to_diagonal, Matter from_down) {
return is_gravity(from_diagonal) && !is_empty(from_down) && is_empty(to_diagonal);
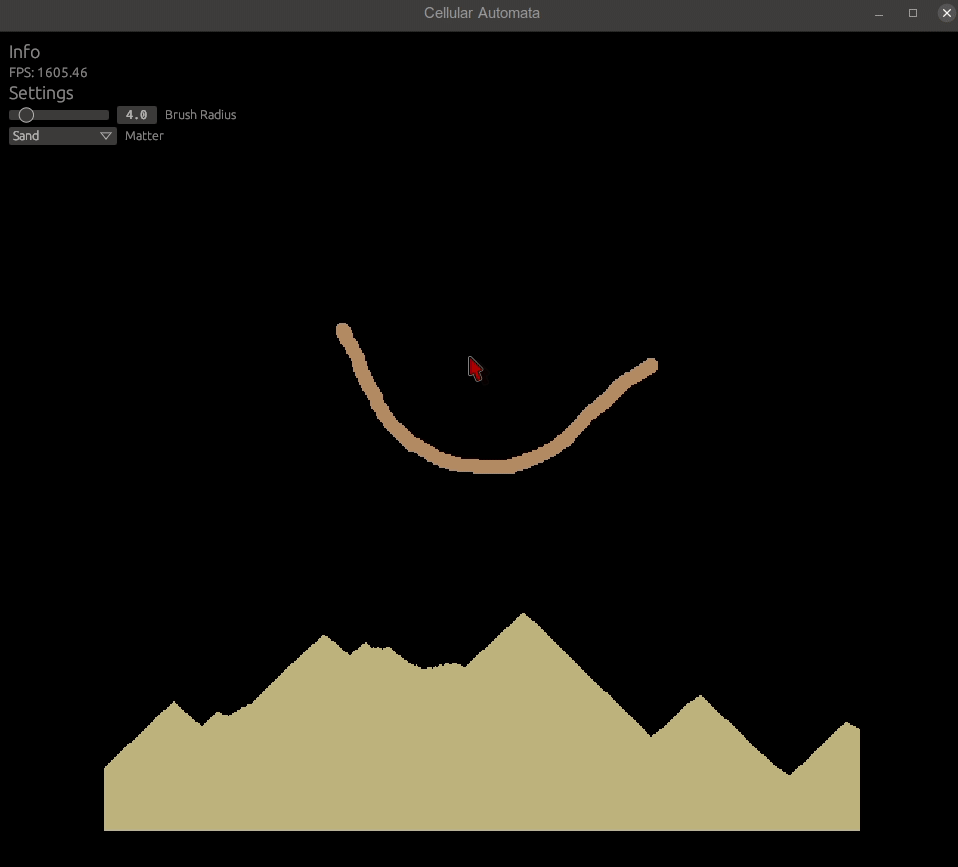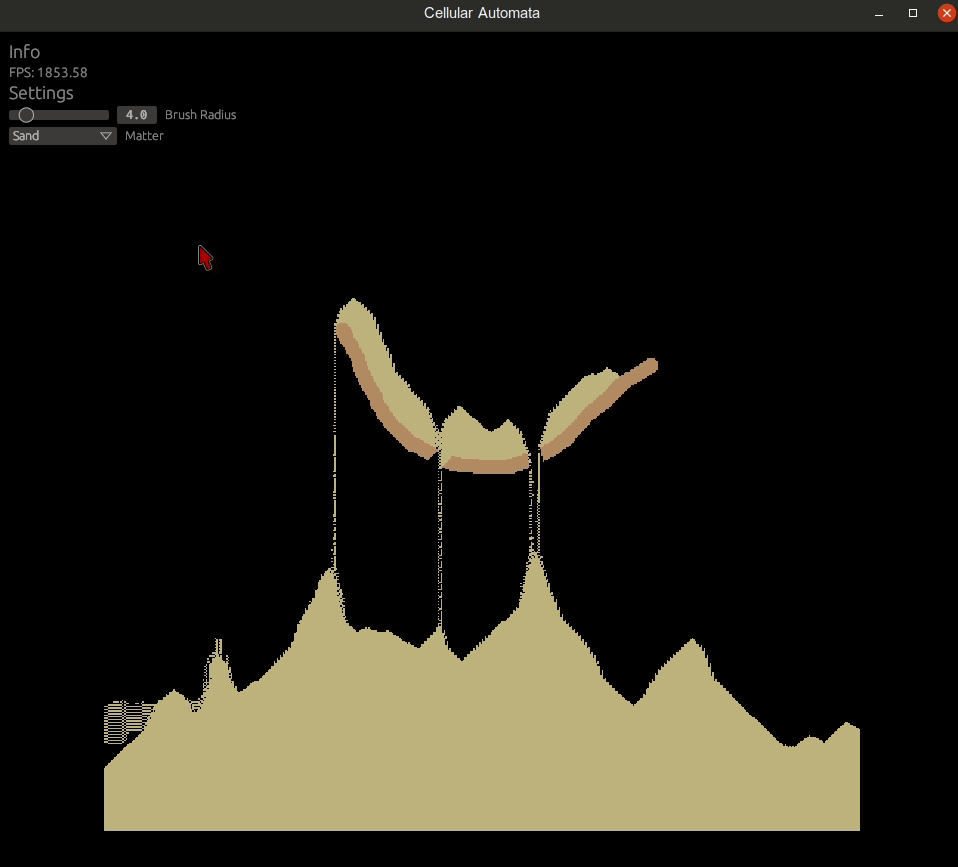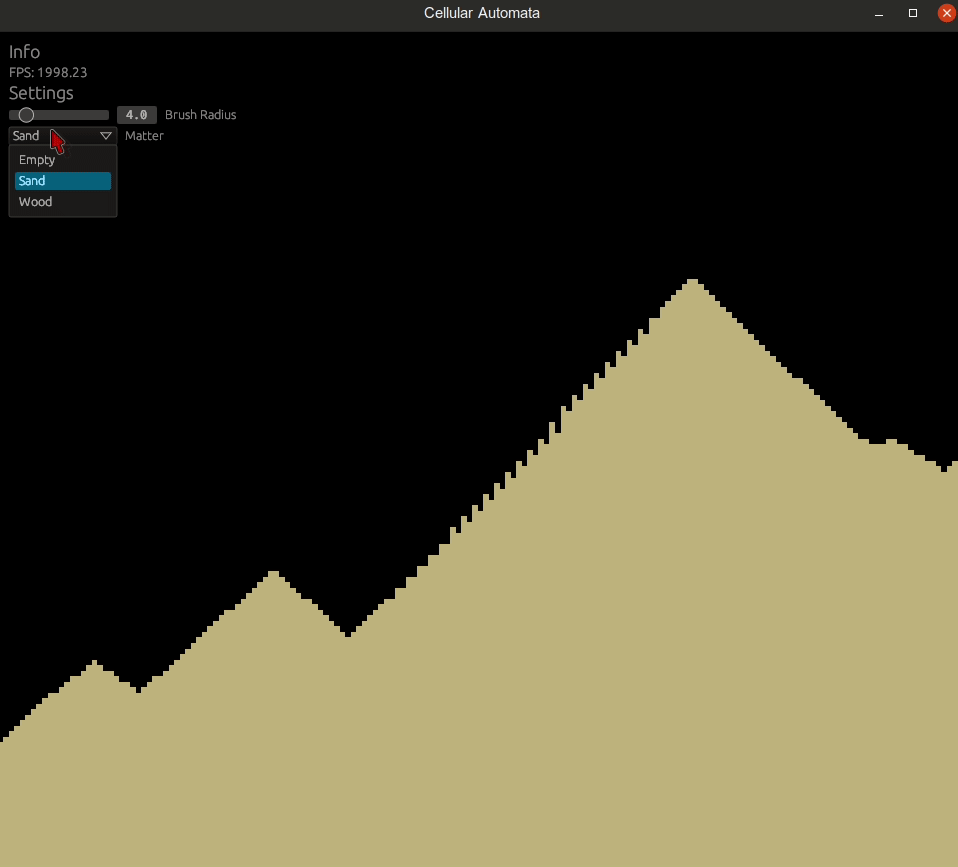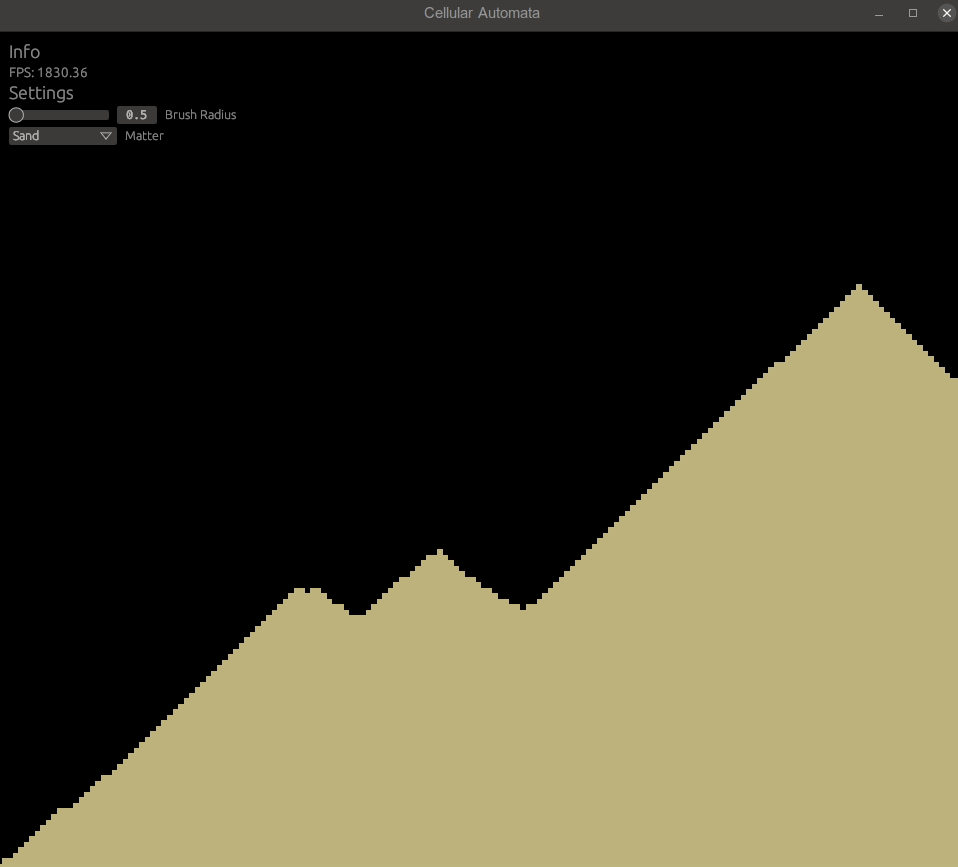
}This helper function does the following: Only matter with gravity can slide, and only if there is no space below and there is space diagonally. Like seen in the example photo below.

Let's add slide_down_empty.glsl to the shaders.
#version 450
#include "includes.glsl"
// Slide down left on empty kernel
void slide_left_empty(ivec2 pos) {
Matter current = read_matter(pos);
Matter down = get_neighbor(pos, DOWN);
Matter right = get_neighbor(pos, RIGHT);
Matter up_right = get_neighbor(pos, UP_RIGHT);
Matter down_left = get_neighbor(pos, DOWN_LEFT);
Matter m = current;
if (!is_at_border_top(pos) && !is_at_border_right(pos) && slides_on_empty(up_right, current, right)) {
m = up_right;
} else if (!is_at_border_bottom(pos) && !is_at_border_left(pos) && slides_on_empty(current, down_left, down)) {
m = down_left;
}
write_matter(pos, m);
}
// Slide down right on empty kernel
void slide_right_empty(ivec2 pos) {
Matter current = read_matter(pos);
Matter down = get_neighbor(pos, DOWN);
Matter left = get_neighbor(pos, LEFT);
Matter up_left = get_neighbor(pos, UP_LEFT);
Matter down_right = get_neighbor(pos, DOWN_RIGHT);
Matter m = current;
if (!is_at_border_top(pos) && !is_at_border_left(pos) && slides_on_empty(up_left, current, left)) {
m = up_left;
} else if (!is_at_border_bottom(pos) && !is_at_border_right(pos) && slides_on_empty(current, down_right, down)) {
m = down_right;
}
write_matter(pos, m);
}
void slide_down_empty(ivec2 pos) {
if ((push_constants.sim_step + push_constants.move_step) % 2 == 0) {
slide_left_empty(pos);
} else {
slide_right_empty(pos);
}
}
void main() {
slide_down_empty(get_current_sim_pos());
}This is a bit more complex than falling down. It's because there are two possible directions. And we need to separate them. If we did not separate inspecting the directions, our threads would run into inconsistent decisions. We could handle left or right with probability that is dependent on the pixel position (a probability that gets the same result per pixel position), but we're just going to do swap the direction of inspection at separate steps.
The idea is that at every other move step we'll be prioritizing the attempt to slide left, and every other step we'll prioritize the attempt to slide right. We'll need push constants for this to pass in the sim step and move steps variables.
Add them to includes to the end of layouts. Sim step represents an entire simulation step at one frame. Move step represents a single movement. One fall is 1 step, One diagonal is another. We'll be enabling multiple movement steps later, so let's add these parameters.
layout(push_constant) uniform PushConstants {
uint sim_step;
uint move_step;
} push_constants;Modify stepping and dispatch and add slide_pipeline.
pub struct CASimulator {
//...
slide_pipeline: Arc<ComputePipeline>, // New
//...
sim_step: u32, // New
move_step: u32, // New
}
pub fn new(compute_queue: Arc<Queue>) -> CASimulator {
//...
// Create pipelines
let (fall_pipeline, slide_pipeline,, color_pipeline) = {
//...
let slide_shader = slide_down_empty_cs::load(compute_queue.device().clone()).unwrap();
//...
(
//...
create_compute_pipeline(
compute_queue.clone(),
slide_shader.entry_point("main").unwrap(),
descriptor_layout.to_vec(),
&spec_const,
),
//...
)
};
CASimulator {
//...
slide_pipeline,
//...
sim_step: 0,
move_step: 0,
}
}
pub fn step(&mut self, move_steps: u32, is_paused: bool) {
//...
if !is_paused {
for _ in 0..move_steps {
self.step_movement(&mut command_buffer_builder, self.fall_pipeline.clone());
self.step_movement(&mut command_buffer_builder, self.slide_pipeline.clone());
}
}
// Finally color the image
self.dispatch(
&mut command_buffer_builder,
self.color_pipeline.clone(),
false,
);
//...
self.sim_step += 1;
}
/// Step a movement pipeline. move_step affects the order of sliding direction
fn step_movement(
&mut self,
builder: &mut AutoCommandBufferBuilder<PrimaryAutoCommandBuffer>,
pipeline: Arc<ComputePipeline>,
) {
self.dispatch(builder, pipeline.clone(), true);
self.move_step += 1;
}
/// Append a pipeline dispatch to our command buffer
fn dispatch(
//...
) {
// New
let push_constants = fall_empty_cs::ty::PushConstants {
sim_step: self.sim_step as u32,
move_step: self.move_step as u32,
};
builder
//...
.bind_descriptor_sets(PipelineBindPoint::Compute, pipeline_layout.clone(), 0, set)
.push_constants(pipeline_layout.clone(), 0, push_constants) // New!
//...
}
mod slide_down_empty_cs {
vulkano_shaders::shader! {
ty: "compute",
path: "compute_shaders/slide_down_empty.glsl"
}
}Last, modify simulate in main.rs and ensure we run the simulation only 60 times per second. This way we can keep our sand fall speed consistent regardless of actual frame rate.
// main.rs
use bevy::time::FixedTimestep;
pub const SIM_FPS: f64 = 60.0;
//...
.add_system(draw_matter)
// Simulate only SIM_FPS times per second. Instead of add_system(simulate)
.add_system_set_to_stage(
CoreStage::Update,
SystemSet::new()
.with_run_criteria(FixedTimestep::steps_per_second(SIM_FPS))
.with_system(simulate),
)
//...
fn simulate(mut sim_pipeline: ResMut<CASimulator>, settings: Res<DynamicSettings>) {
sim_pipeline.step(1, settings.is_paused);
}Now you'll be able to simulate sandfall!
Let's finish this with an example how you can test your compute shader logic:
// Add query matter functionality
/// Query matter at pos
pub fn query_matter(&self, pos: IVec2) -> Option<MatterId> {
if self.is_inside(pos) {
let matter_in = self.matter_in.read().unwrap();
let index = self.index(pos);
Some(MatterWithColor::from(matter_in[index]).matter_id())
} else {
None
}
}
#[cfg(test)]
mod tests {
use bevy::math::IVec2;
use vulkano_util::context::VulkanoContext;
use crate::{ca_simulator::CASimulator, matter::MatterId};
fn test_setup() -> (VulkanoContext, CASimulator) {
// Create vulkano context
let vulkano_context = VulkanoContext::default();
// Create Simulation pipeline
let simulator = CASimulator::new(vulkano_context.compute_queue());
(vulkano_context, simulator)
}
#[test]
fn test_example_sandfall() {
let (_ctx, mut simulator) = test_setup();
let pos = IVec2::new(10, 10);
// Empty matter first
assert_eq!(simulator.query_matter(pos), Some(MatterId::Empty));
simulator.draw_matter(&[pos], 0.5, MatterId::Sand);
// After drawing, We have Sand
assert_eq!(simulator.query_matter(pos), Some(MatterId::Sand));
// Step once
simulator.step(1, false);
// Old position is empty
assert_eq!(simulator.query_matter(pos), Some(MatterId::Empty));
// New position under has Sand
assert_eq!(
simulator.query_matter(pos + IVec2::new(0, -1)),
Some(MatterId::Sand)
);
}
}While developing a graphical application, you may want to test your logic with graphics. If you see things working correctly, they likely are. However, unit tests can be very helpful if you get stuck.
We'll need a windowless VulkanoContext which will allow access to the device's compute queue. Thus we can create our simulator and test it after drawing and simulating. Simple!
For visual testing, you can add the ability to pause your simulation and tooltips for matter:
// gui.rs
pub fn user_interface(
//...
windows: Res<Windows>,
camera: Res<OrthographicCamera>,
simulator: Res<CASimulator>,
) {
//...
let primary = windows.get_primary().unwrap();
if primary.cursor_position().is_some() {
let world_pos = cursor_to_world(primary, camera.pos, camera.scale);
let sim_pos = MousePos::new(world_pos).canvas_pos();
egui::containers::show_tooltip_at_pointer(&ctx, egui::Id::new("Hover tooltip"), |ui| {
ui.label(format!("World: [{:.2}, {:.2}]", world_pos.x, world_pos.y));
ui.label(format!("Sim: [{:.2}, {:.2}]", sim_pos.x, sim_pos.y));
if let Some(matter) = simulator.query_matter(sim_pos.as_ivec2()) {
ui.label(format!("Matter: {:?}", matter));
}
});
}
}// main.rs
fn input_actions(
//...
mut settings: ResMut<DynamicSettings>,
) {
//...
// Pause
if keyboard_input.just_pressed(KeyCode::Space) {
settings.is_paused = !settings.is_paused;
}
}Now you have some debugging capability, if you wish to improve (complicate) the simulation logic.

Next we will improve the matter colors and add some optional finishing touches to the application. Mainly performance optimizations.
You can checkout the full source code for this part of the tutorial here
Give feedback here
Was this page helpful?